We propose Visualize-then-Retrieve (VisRet), a new paradigm for Text-to-Image (T2I) retrieval that mitigates the limitations of cross-modal similarity alignment of existing multi-modal embeddings.
Methodology
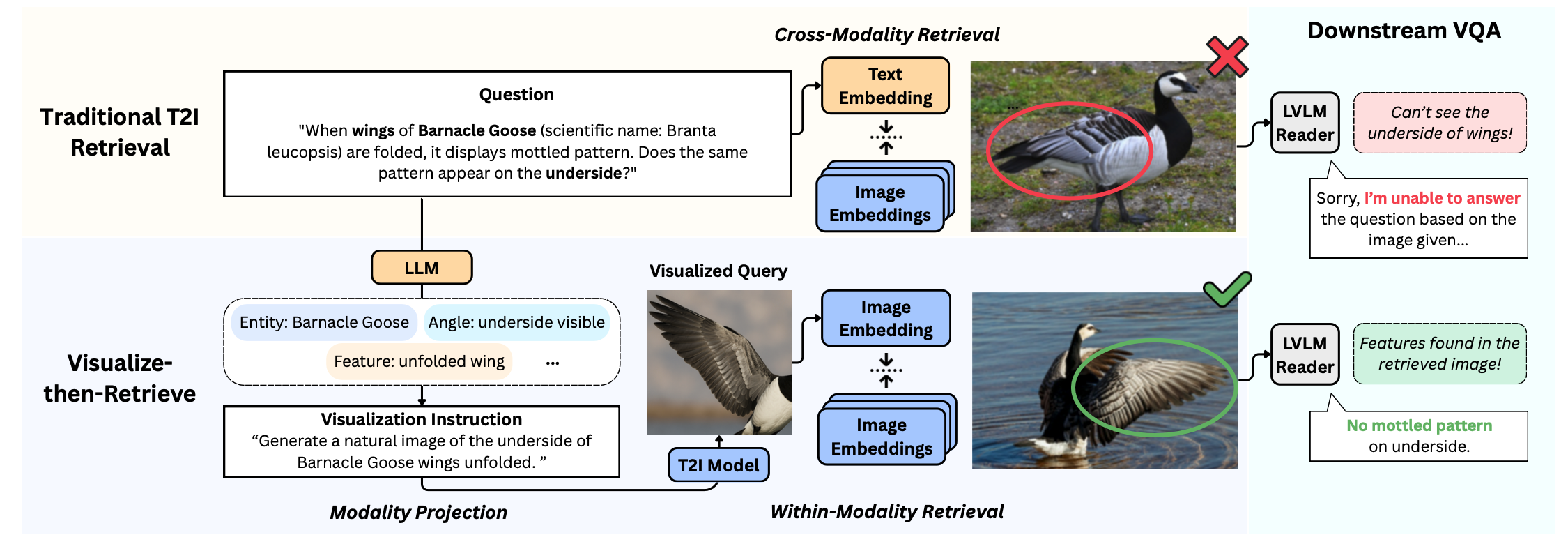
We introduce Visual-RAG-ME, a new benchmark for evaluating T2I retrieval and knowledge-intensive VQA. It contains 50 high quality queries on comparing the visual features between two similar organisms.




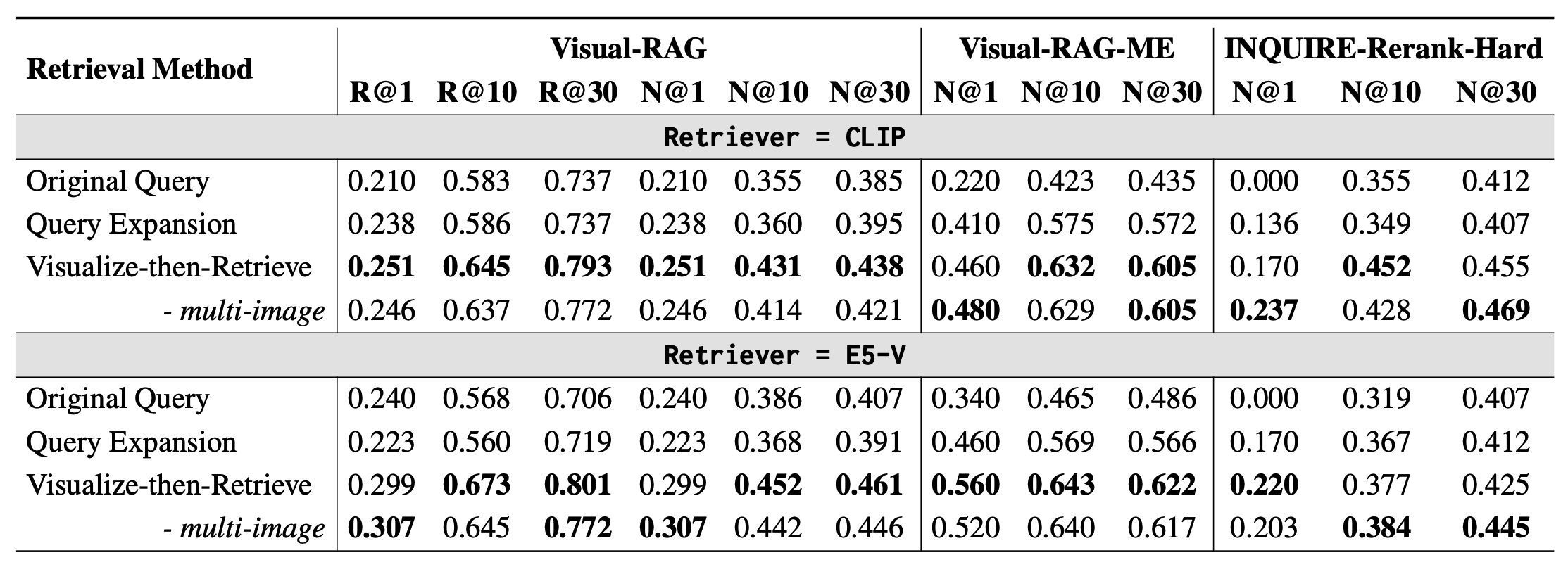
Evaluation results across three T2I retrieval benchmarks using different retrieval strategies and retrievers. We use GPT-4o for T2I instruction generation and GPT-Image-1 for T2I generation. The best results in each column within each retriever group are boldfaced. R = Recall. N = NDCG.
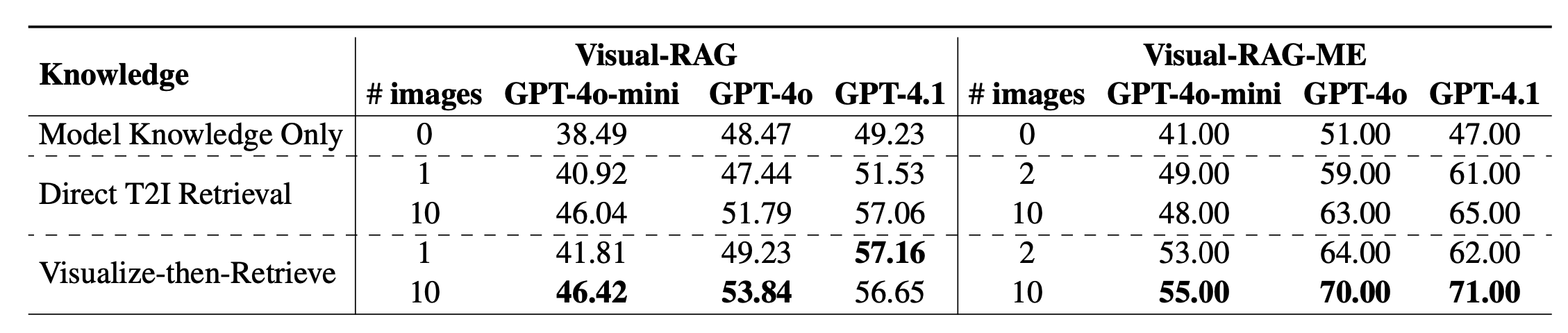
VQA performance comparison using different LVLMs as instruction generators for VisRet and query rephrase models. CLIP is used as the retriever. Boldfaced numbers indicate the best in each column.
@article{wu2025visualizedtexttoimageretrieval,
title={Visualized Text-to-Image Retrieval},
author={Di Wu and Yixin Wan and Kai-Wei Chang},
year={2025},
eprint={2505.20291},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2505.20291},
}